
Standard kodowania MPEG-2.
Szybki rozwój technik cyfrowych pociąga z a sobą coraz szersze wykorzystywanie cyfrowych sygnałów fonicznych. Cyfryzacja sygnałów pozwala na uzyskiwanie szeregu zalet, zarówno jakościowych jaki i operacyjnych, wiąże się jednak ze wzrostem szerokości pasma sygnałów, gdyż sygnał cyfrowy zajmuje znacznie większą
szerokość pasma niż sygnał analogowy reprezentujący ten sam dźwięk. Przykładowo, przesyłanie sygnału stereofonicznego z rozdzielczością 16 bitów (jakość CD) i częstotliwością próbkowania 48 kHz (standard studyjny), wymaga przepustowości ponad 1,5 Mb/s. Zapisanie zaledwie 1 minuty takiego sygnał w pamięci cyfrowej wymaga pojemności ponad 11 Mbyte.Ze względów ekonomicznych nie jest możliwe zwiększenie przepustowości kanałów transmisyjnych ani też pojemności nośników używanych do zapisu sygnału cyfrowego. Stąd od chwili powstania koncepcji cyfryzacji sygnałów fonicznych rozpoczęto prace nad kompresją tych sygnałów. Opracowano wiele algorytmów bezstratnych (kody Huffmana, LZW), a także algorytmy stratne związane z częściową utratą tzw. informacji nadmiarowej,
które wymagają dużych mocy obliczeniowych i dużej szybkości działania.W 1988 roku powstała grupa robocza WG 11 połączonych Komisji Technicznych ISO i IEC, nazywana powszechnie
Moving Picture Expert Group czyli w skrócie MPEG, która 1993 roku opracowała pierwszy standard kompresji sygnału MPEG-1, a 1994 roku MPEG-2, który został on zatwierdzony jako standard ISO/IEC 13818 - Generic coding of moving pictures and associated audio information.2. Opis standardu MPEG-2.
MPEG-2 opiera się o kodowanie percepcyjne które jest formą kompresji stratnej, które do zmniejszenia ilości informacji wykorzystuje dwie właściwości słuchu ludzkiego - próg słyszalności i zjawisko maskowania.
Standard ten zawiera trzy części: systemową, video i audio. Część systemowa definiuje strukturę pakietu do multipleksowania strumieni audio i video w jeden strumień danych, wraz z informacjami synchronizującymi niezbędnymi do dekodowania. Część video do kodowania wykorzystuje między innymi DCT (dyskretna transformata cosinusowa) i p
rzy pracy z przepływnościami rzędu 2-8 Mbit/s (max. 15 Mb/s) zapewnia jakość stosowaną do emisji programów w telewizji. Część audio składa się z trzech algorytmów (trzy warstwy - ang. Layer) o wzrastającej złożoności, wprowadzanym opóźnieniu i efektywności kodowania. Standard wymaga jednak, aby najbardziej złożona warstwa umożliwiała dekodowanie najmniej złożonej Dopuszczalne częstotliwości próbkowania i przepływności obrazuje rysunek 1Przepływność 256 kb/s odpowiada 6-cio krotnej kompresji w stosunku do oryginalnego sygnału CD.
Rys.1.
Możliwa jest praca w następujących trybach:
3. Ogólna zasada kodowania percepcyjnego dla MPEG.
Uproszczoną strukturę koder
a i dekodera percepcyjnego zgodnego z MPEG-2 przedstawia rysunek 2.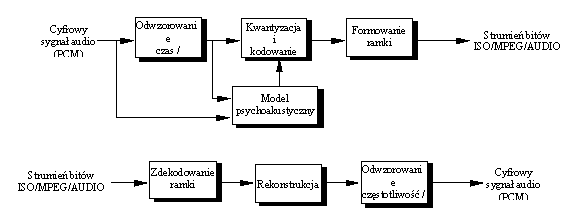
Rys.2. Uproszczona struktura kodeka percepcyjnego MPEG-2.
Na wejście systemu podawany jest cyfrowy sygnał audio PCM. Dla przypomnienia modulacja kodowo-impulsowa PCM składa się z następujących kroków:
Operacja kwantowania sygnału określa próbki z dokładnością 1/2 kroku kwantowania. Wynika to z faktu przyporządkowywania wszystkim wartościom z określonego przedziału tej samej wartości dyskretnej. Błędy kwantowania powodują w odbieranym sygnale efekt szumu nazywanego szumem kwantowania. Amplituda szumu kwantowania zależy więc od liczby przedziałów kwantowania. Nie można jednak zwiększać ilości przedziałów kwantowania gdyż prowadzi to do zwiększenia ilości infor
macji. Jednym ze sposobów ograniczenia przepływności jest wprowadzenie kwantowania dynamicznego, w którym odległości między poziomami kwantowania są różne dla różnych amplitud sygnału. Stosuje się też kwantowanie nierównomierne, różniczkową modulację kodowo-implsową, modulację delta.Następnie wejściowe sygnały foniczne są przekształcane z dziedziny czasu w dziedzinę częstotliwości przy wykorzystaniu zestawu filtrów dzielącego widmo sygnału na 32 podpasma.
Aby szum kwantyzacji nie był słyszalny musi się on znajdować poniżej krzywej progu słyszalności ucha ludzkiego. Ponieważ charakterystyka tego progu zależy od częstotliwości (rys. 3a), w przypadku kwantowania sygnałów szerokopasmowych konieczna jest odpowiednio duża liczba poziomów kwantowania, by szum k
wantowania znalazł się poniżej minimum charakterystyki częstotliwościowej progu. W celu zredukowania przepływności sygnału stosuje się podział pasma sygnału na podpasma (rys. 3b). Wówczas w każdym podpasmie dopuszczalny jest inny poziom szumów, co umożliwia stosowanie w podpasmach o wyżej położonym progu słyszalności mniejszej liczby przedziałów kwantowania.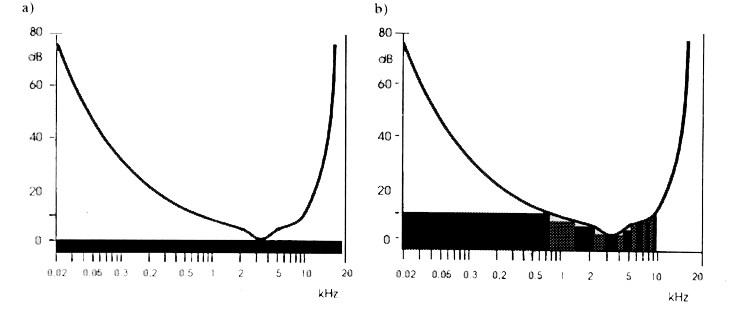
Rys.3. Dopuszczalny poziom szumu kwantowania.
Częstotliwość próbek fonicznych w każdym paśmie jest następnie zmniejszana 32 razy (podpróbkowanie); następnie próbki są kwantowane. Dokładność kwantowania w poszczególnych podpasmach jest różna, wykorzystuje się tu zdolności maskowania, jakie wykazuje ludzki słuch. Model psychoakustyczny oblicza ledwo zauważalny poziom szumów dla każdego podpasma i tak d
obiera dokładność kwantowania w tym paśmie, żeby szum kwantyzacji znajdował się poniżej progu maskowania.W przypadku złożonych sygnałów fonicznych, występuje zjawisko maskowania (zagłuszania) niektórych tonów przez tony o większej amplitudzie. Jest to równoznaczne z podwyższeniem w pewnym obszarze progu słyszalności (rys. 4).
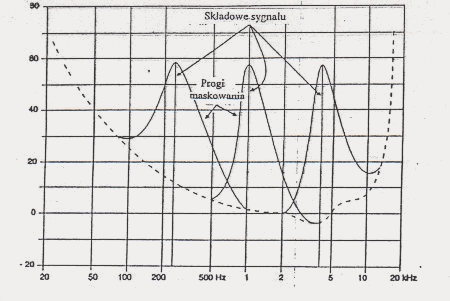
Rys.4. Efekt maskowania tonów tonami.
Równocześnie występujące dominujące harmoniczne chwilowego sygnału tworzą w swym sąsiedztwie strefy maskowania zmieniające dynamicznie próg słyszalności ucha. Strefy maskowania składowych w bliskich odstępach częstotliwości nakładają się. Zmieniający się dynamicznie przebieg krzywej progowej pozwala na stosowanie mniejszej liczby bitów do kodowania próbek, ze względu na dopuszczalny większ
y poziom szumów w podpasmach. Wymaga to periodycznego wyliczania progu maskowania oraz minimalnej liczby poziomów kwantowania gwarantującej maskowanie szumu kwantowania w kolejnych podpasmach (rys. 5).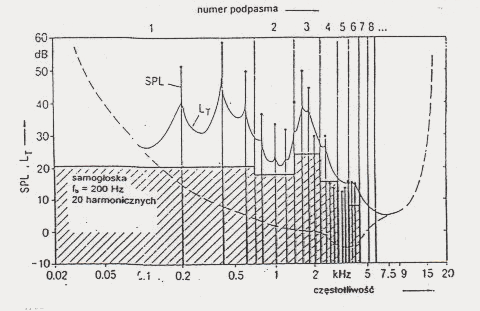
Rys.5. Efekt maskowania dźwiękiem złożonym.
Skwant
owane wartości próbek przesyła się razem ze współczynnikami skalowania do układu formatującego strukturę ramki fonicznej.Dekodowanie sygnału przebiega w odwrotnej kolejności, tyle, że pominięty jest tutaj model psychoakustyczny. Jest to najbardziej złożony blok, dlatego kodowanie przeprowadza się w taki sposób, aby detekcja nie wymagała jego użycia. Jest to również korzystne ze względów ekonomicznych, gdyż zmniejszenie dzięki kompresji przepływności kanału odbywa się kosztem wykonania pojedynczego egzem
plarza modelu psychoakustycznego w urządzeniu nadawczym, bez konieczności używania go w wielu odbiornikach.4. Warstwy kodowania.
Norma opisująca standard MPEG zawiera trzy warstwy kodowania różniące się złożonością i stopniem kompresji.
Warstwa pierwsza przeznaczona jest raczej do zastosowań nieprofesjonalnych, dla których silna kompresja nie jest decydująca. Algorytmy tej warstwy analizują grupy po 384 próbek wejściowego kodu PCM.
Warstwa druga wprowadza dalszą kompresję kodu wejściowego przez łączną analizę po trzy grupy próbek PCM (3*384=1152) w jednej ramce i redukcję elementów powtarzających się lub bliskich. Dla zadanej przepływności kodera warstwa ta gwarantuje wyższą jakość dźwięku niż warstwa 1.
Schemat blokowy kodera dla warstwy I i II prze
dstawia rysunek 6. Technika kodowania dla tych warstw oparta została na: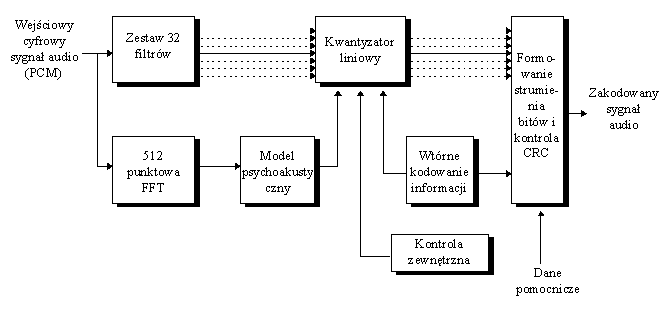
Rys. 6. Schemat blokowy kodera MPEG dla warstwy I i II.
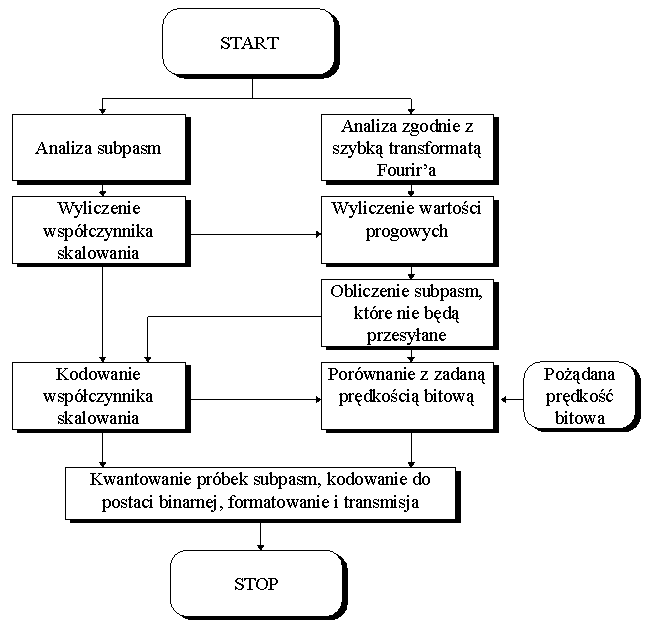
Rys. 7. Algorytm kodowania kanału monofonicznego dla warstw I i II.
Format zakod
owanego strumienia bitów dla warstw I i II pokazano na rysunku 8. W ramce można wyróżnić cztery podstawowe obszary: nagłówek, CRC (opcjonalnie), dane audio i dane pomocnicze.Nagłówek:
Nagłówek jest 32 bitowym polem zawierającym takie parametry jak numer warstwy, częstotliwość próbkowania i dane zarządzające resztą ramki,
CRC:
CRC (kod detekcji błędów) jest stosowany opcjonalnie i to czy jest stosowany czy też nie, jest wyspecyfikowane w nagłówku. Jeśli jest stosowany jego długość wynosi 16 bitów. Nie używa się go najczęściej w przypadku systemów zapisu sygnału audio na dyski twarde.
Kontrola błędu uruchamiana jest dla zerowej wartości bitu kontroli w nagłówku. Wykorzystuje cykliczny kod nadmiarowy CRC, z wielomianem generującym G(x)=x
16+ x15+ x2+1. Służy on do wykrywania błędów wśród 16 bitów nagłówka poczynając od wskaźnika przepływności z 5 pola. Pierwsze 16 bitów nagłówka nie musi być chronionych, gdyż zawiera powtarzające się informacje.Dane audio:
Obszar danych audio zawiera skompresowany dźwięk. Długość obszaru jest zmienna i zależy od stopnia kompresji, warstwy algorytmu oraz wskaźnika trybu pracy kodera podanych w nagłówku. Najczęściej wykorzystywane tryby pracy to:
Dane pomocnicze:
Dane pomocnicze to dowolnie definiowane przez użytkownika pole o zmiennej długości.
Pole uzupełniające to dopełnienie zerami do pełnej ramki pozostałych pól począwszy od końca pola kodów próbek do kodu synchronizacji następnej ramki. Długość tego pola jest zależna od długości pola danych. W radiofonii DAB i transmisji wielokanałowej część pola uzupełniającego wykorzystuje się do przesyłania danych dodatkowych.
W transmisji wielokanałowej zawiera dane dla kanałów dodatkowych.
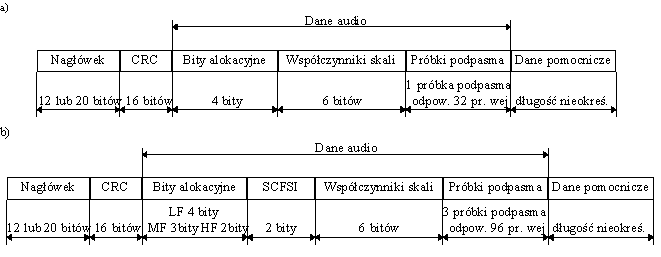
Rys. 8. Strumień bitów dla MPEG a) format ramki dla warstwy I, b) format ramki dla warstwy II.
Warstwa trzecia wprowadza większą liczbę podpasm filtracji sygnału wejściowego. Algorytmy tej warstwy umożliwiają transmisję dźwięku wysokiej jakości kanałem o bardzo małej przepływności (poniżej 64 kbit/s).
Warstwa III MPEG-2 jest przeznaczona dla przekazywania dźwięku wielokanałowego, podobnie jak warstwa II, ale zastosowano tu dodatkowo zmodyfikowaną transformacje kosinusową MDCT. Po podziale widma sygnału na 32 podpasma, MDCT dzieli każde podpasmo na 18 lini. Dokładność kwantowania próbek w każdej linii jest osobno ustalana przez model psychoakustyczny. Schemat blokowy kodera warstwy III przedstawia rysunek 9.
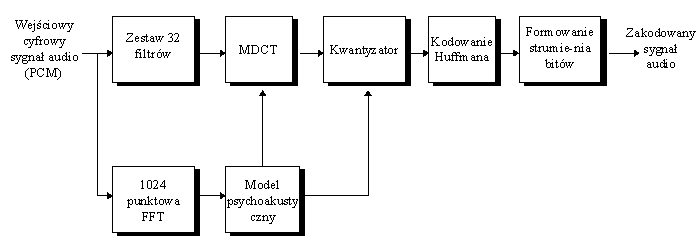
Rys. 9. Koder MPEG-2 warstwa III (jeden kanał).
Zadaniem pętli kwantyzacji jest reprezentowanie próbek w każdym paśmie częstotliwości za pomocą minimalnej liczby bitów potrzebnych do utrzymania szumów kwantyzacji poniżej progu maskowania. Warstwa III wykorzystuje kwantyzer nieliniowy - stopnie kwantowania rosną ze wzrostem amplitud próbek. Skwantowana informacja jest następnie kodowana za pomocą kombinacji kodowania ciągów RLC i kodowania Huffmana. W wyższych pasmach częstotliwości próbki są często
kwantowane jako zerowe, stąd pasma te można efektywnie kodować za pomocą ciągów bitów. Pozostałe pasma są dzielone na grupy i wykorzystują standardowe tablice Huffmana. Zakodowane dane tworzą pakiety elementarne, uzupełnione czołówką i dodatkowymi informacjami przekazywanymi do dekodera.5. Podsumowanie.
W ciągu ostatnich 10 lat kodowanie percepcyjne przebyło drogę od pierwszych projektów badawczych do komercyjnych aplikacji. Ta technika kompresji znajduje zastosowanie w coraz większej liczbie systemów jak choćby znany od dawna Mini Disc czy DCC, multimedia komputerowe i kino domowe. Prace związane z rozwojem kodeków percepcyjnych zmierzają do uzyskania jak najlepszej jakości sygnału, przy jednoczesnej minimalizacji przepływności systemu. W zależności od
potrzeb użytkownika standard MPEG zapewnia różne formy kodowania od warstwy I, charakteryzującej się bardzo prostą implementacją kodera, do warstwy III zapewniającej dobrą jakość dźwięku przy przepływności 64 kbit/s na kanał.6. Literatura: